Domingo, 21h. O celular vibra. Na tela, uma mensagem do CEO ou do Diretor de Vendas: “O sistema está lento de novo?” ou “Ninguém consegue acessar o ERP!”. Nesse momento, o coração acelera. De repente, o fim de semana acabou. Assim, começa a corrida para mobilizar a equipe, analisar logs e, essencialmente, apagar um incêndio no coração da própria empresa.
Se essa cena é familiar, então você sabe que cada incidente não é apenas um bug. Na prática, ele representa uma rachadura na confiança da empresa na tecnologia que deveria sustentá-la. Além disso, significa que uma equipe de TI talentosa e cara precisa interromper projetos de inovação para resolver problemas que poderiam ter sido evitados.
Hoje, a maioria das equipes de TI opera em modo reativo: algo quebra e nós consertamos. No entanto, existe outra possibilidade. E se, em vez disso, fosse possível identificar um problema antes mesmo de ele acontecer? Ou seja, antes que ele paralise um departamento inteiro?
Por isso, chegou a hora de parar de agir como bombeiro e assumir o papel de arquiteto da estabilidade operacional.
É hora de parar de ser o bombeiro e se tornar o arquiteto da estabilidade operacional.
1. O Problema Real: Uma Falha Técnica é a Paralisia Operacional
Quando o sistema interno de uma empresa falha, não se trata apenas de um inconveniente técnico. Na verdade, o impacto se espalha rapidamente por toda a operação.
Por exemplo, se o ERP fica lento, a logística deixa de processar pedidos e o financeiro não consegue faturar.
Da mesma forma, se o CRM trava, o time de vendas para de emitir propostas e perde oportunidades.
Além disso, quando o sistema de produção falha, toda a linha de montagem pode ser interrompida.
Nesse cenário, um simples erro 500 deixa de ser um problema técnico e passa a ser um problema de negócio.
Consequentemente, a confiança dos outros departamentos na equipe de TI diminui a cada incidente. Por esse motivo, garantir estabilidade nos sistemas internos não é apenas uma funcionalidade adicional. Pelo contrário, é a base que permite que todas as outras áreas façam seu trabalho.
2. A Mudança de Visão: De Reativo para Proativo
O monitoramento tradicional foca em falhas catastróficas. Ele te avisa quando o servidor caiu. É útil, mas é tarde demais. A operação já parou.
O monitoramento proativo, ou observabilidade, é diferente. Ele não procura apenas por “quedas”; ele procura por “comportamentos estranhos” que são o prenúncio de uma falha. Ele te avisa quando:
- O tempo de resposta de uma consulta ao banco de dados do ERP começa a aumentar lentamente.
- A taxa de erros em uma integração entre o CRM e o sistema de marketing sobe de 0.1% para 1%.
- O consumo de memória de uma aplicação crítica começa a crescer de forma anormal, indicando um problema que derrubará o sistema em algumas horas.
A ideia é prever falhas em sistemas ao detectar as anomalias que as precedem, dando a você tempo para agir antes que o incêndio comece.
3. O Benefício Prático: Menos Estresse, Mais Confiança e Redução de Custos
Adotar uma abordagem proativa traz benefícios imediatos e tangíveis:
- Menos Estresse para a Equipe de TI: A paz de espírito de ter um “sistema de alerta precoce” é imensurável. As noites e fins de semana voltam a ser para descanso, não para plantões de emergência.
- TI como Habilitador, Não como Gargalo: A TI deixa de ser o departamento que “só resolve problemas” e passa a ser o parceiro estratégico que garante a estabilidade para que as outras áreas atinjam suas metas. A confiança na sua equipe aumenta exponencialmente.
- Redução de Custos Operacionais: Menos incidentes significam menos horas extras, menos perda de produtividade em toda a empresa e menos recursos gastos em suporte emergencial. O investimento em observabilidade se paga rapidamente.
4. Como a BobBytes Faz Isso: Inteligência em Vez de Alertas
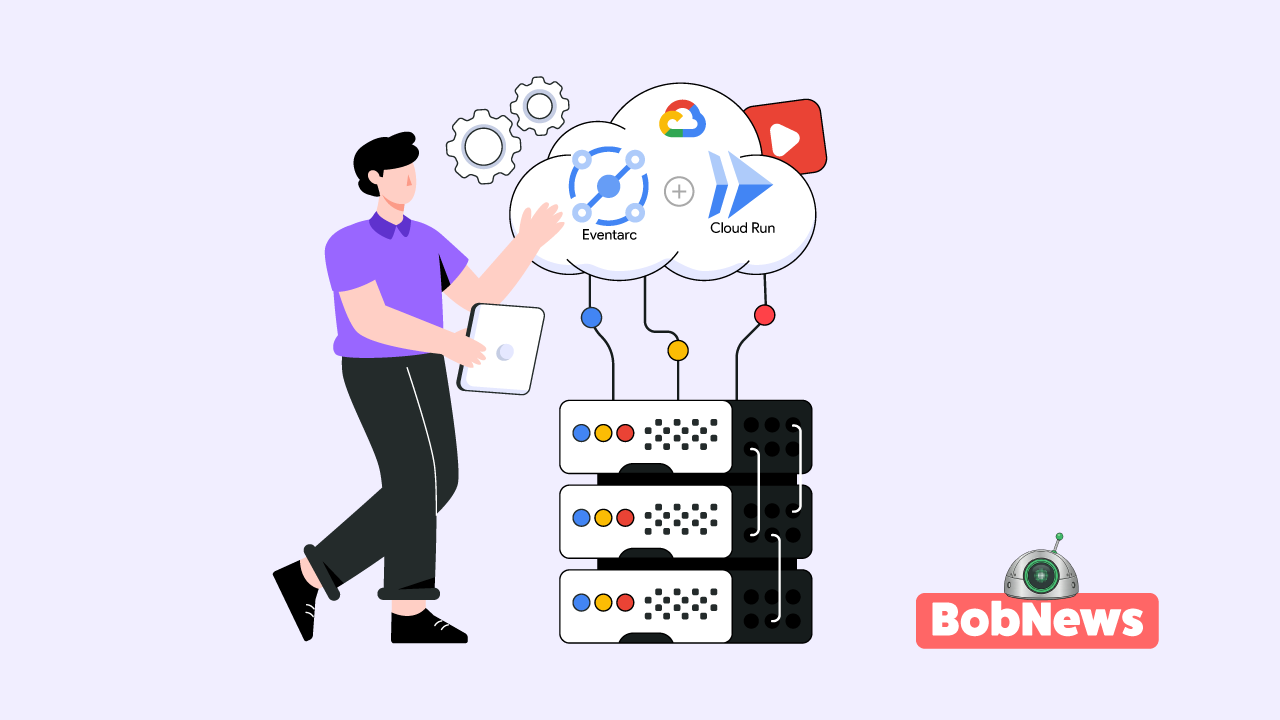
Transformar essa visão em realidade requer uma estratégia. Na BobBytes, nós implementamos essa camada de inteligência usando a suíte Google Cloud Operations (anteriormente Stackdriver).
- Coleta Centralizada: Integramos os Logs, Métricas e Traces de todas as suas aplicações internas críticas em um único lugar.
- Detecção de Anomalias com IA: Usamos a Inteligência Artificial do Google Cloud para que ela aprenda o “comportamento normal” do seu sistema. Quando um desvio desse padrão é detectado, ela gera um alerta inteligente e contextualizado.
- Dashboards de Causa Raiz: Criamos painéis de observabilidade que não apenas mostram o que está estranho, mas também ajudam a identificar por que, permitindo uma resolução de problemas muito mais rápida.
De Bombeiro a Arquiteto: Assuma o Controle da Estabilidade
Continuar no ciclo de “apagar incêndios” é uma escolha que define o papel da sua equipe de TI: sempre correndo atrás do prejuízo, sempre em modo de defesa. É uma posição de estresse constante que drena a capacidade de inovação.
A alternativa é mudar essa identidade. Adotar uma abordagem proativa com observabilidade inteligente é reivindicar o papel de arquiteto — aquele que projeta e constrói sistemas resilientes, que antecipa problemas e que garante a estabilidade como um pilar estratégico do negócio. É sobre ter o controle, a previsibilidade e, finalmente, a tranquilidade de saber que você está sempre um passo à frente da crise.
Cansado de ser o bombeiro da sua empresa? Fale com nossos especialistas em estabilidade de sistemas e descubra como o monitoramento proativo do Google Cloud pode transformar sua operação e trazer a previsibilidade que você precisa.